基本概念
基本组件
集群:
由不同节点组成。整个 Elasticsearch 集群的核心就是对所有的分片执行分布存储,索引,负载,路由的工作。
节点:
单个服务器,用于保存数据、搜索文档
索引:
类似 数据库,可以定义多种类型的映射,映射到一个或多个主分片中,可以有 0 个、多个副本分片
文档:
类似数据库中的一行数据,可以有不同的结构(字段)
分片(Shard) :
分片的个数在索引创建时被定义,不能动态修改。
每个分配都是单独的 lucene 实例,多分片可以分散数据和负载,增加并行度和吞吐量
是集群数据的容器,Index(索引)被分为多个文档碎片存储在分片中,分片又被分配 到集群内的各个节点里。
当需要查询一个文档时,需要先找到其位于的分片。也就是说,分片是 Elasticsearch 在集群内分发数据的单位。
每个分片都是一个 Lucene 索引实例,您可以将其视作一个独立的搜索引擎,它能够对 Elasticsearch 集 群中的数据子集进行索引并处理相关查询。
主分片(Primary Shard):
分片的类型,负责写入数据
默认为 1 个
副本分片(Replica Shard):
是主分片的副本,提供搜索、返回文档的服务。支持横向扩展,增大数量有利于增加吞吐量
主分片出异常的情况下,会从副本分片中自动进行选举出新的主分片
默认为 0 个,但生产环境上,最少为一个
路由(Route)
默认情况下, 在 es 中存放数据时会根据文档 id 平均存放到所遇到分片中。导致查数据的时候,需要查所有的分片才能得到结果。
默认情况的分片算法:
shard_num = hash(_routing) % num_primary_shards
为了避免扫描全部分片,因此需要自定义路由规则,将文档放到指定的分片上去,查询的时候,只查指定的分片即可得到结果
集群的节点类型:
- 主节点(Master-eligible node) :集群层面的管理,例如创建或删除索引、跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。任何不是仅投票主节点的合格主节点都可以通过主选举过程被选为主节点。
- 专用备选主节点(Dedicated master-eligible node) : Elasticsearch 集群中,设置了只能作为主节点的节点。设置专用主节点主要是为了保障集群增大时的稳定性,建议专用主节点个数至少为 3 个。
- 仅投票主节点(Voting-only master-eligible node): 仅参与主节点选举投票,不会被选为主节点,硬件配置可以较低。
- 数据节点(data node) :数据存储和数据处理比如 CRUD、搜索、聚合。
- 预处理节点(ingest node) :执行由预处理管道组成的预处理任务。
- 仅协调节点(coordinating only node) :路由分发请求、聚集搜索或聚合结果。
- 远程节点(Remote-eligible node) :跨集群检索或跨集群复制。
Luence 的关键概念
- term:关键字
- postings list:位置表
即包含所有关键字的文档id集合,被处理为整形id
luence 的写入流程
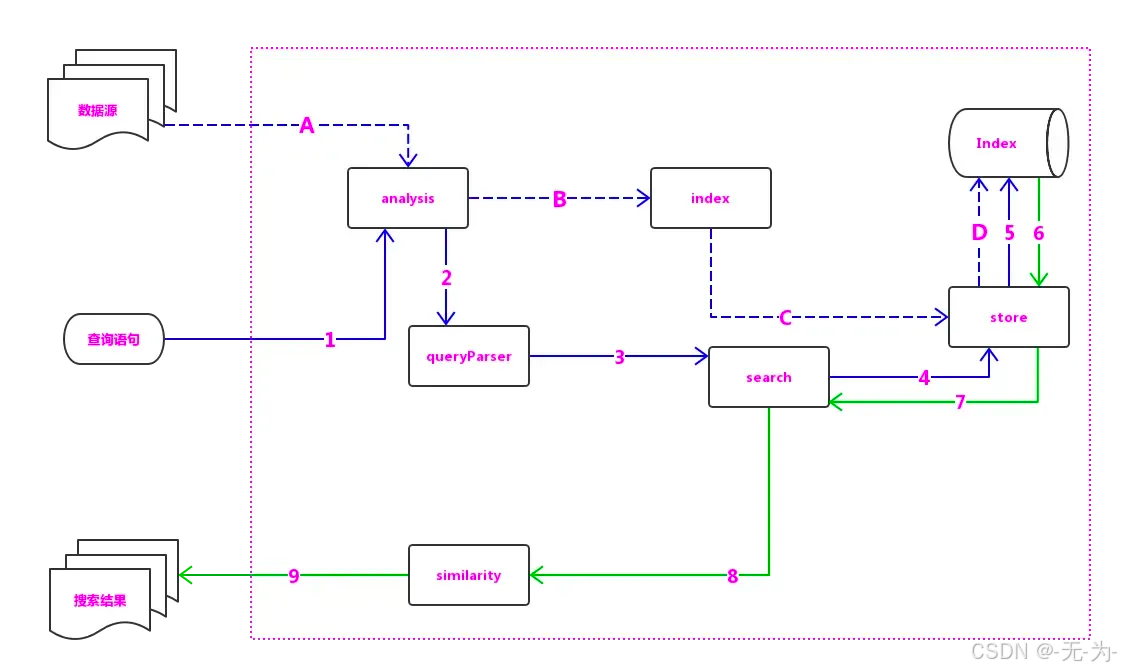
索引原理:
倒排索引:
字典树 Trie,树状结构,hash 树的变种
有限状态转移机
索引压缩、优化
分段存储
延时写策略
段合并
关键流程
写入流程
如下图
常见问题
如何保存数据一致
通过版本号使用乐观锁控制,确保新版本不会被旧版本覆盖
写操作:
三种分布式一致性级别
读操作:
可设置 replication
-
= sync(默认同步),来使主分片和副本分片都返回结果,才返回给客户端
-
= async 是,可以设置查询 参数来确保数据为最新的
如何与 mysql 保持数据同步
全量、增量、增全量、binlog 同步
参考:
- 1、【Elasticsearch 如何做到快速检索 - 倒排索引的秘密】https://segmentfault.com/a/1190000037658997
- 2、【关于Lucene的词典FST深入剖析】https://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/
- 3、【科普文:深入理解ElasticSearch体系结构】https://blog.csdn.net/Rookie_CEO/article/details/140088756
- 4、https://www.cnblogs.com/jajian/p/11223992.html



